

Learn how to build production-grade document understanding systems using LLMs, optionally using private, high-performance models provided by NVIDIA NIM hosted in your account.
Companies possess troves of unstructured data: support tickets, medical records, incident reports, screenplays, patents - the list is endless.
Just two years ago, analyzing the contents of unstructured documents automatically was a highly complex endeavor, often requiring PhD-level expertise in natural language processing. Even with this expertise, the results were not guaranteed. Consequently, only companies with advanced R&D departments ventured into experimenting with automatic document understanding.
Today, thanks to now-ubiquitous large language models, any company with a few software engineers can quickly prototype sophisticated solutions for processing various types of unstructured data. Despite their well-known flaws, the LLMs of today are pragmatic tools that can unlock a vast amount of previously underutilized data for automatic processing and analysis.
Getting started with document understanding
Typically, the initial iterations of new technologies are not easily accessible to non-experts — consider the first PCs or the early Internet. Not so in the case of LLMs. Literally anyone can copy and paste a document into ChatGPT or a similar service, ask a question in plain English, and receive a response in real time.
Ironically, the most cumbersome part of this process may be manually copy-pasting documents into a chat window. Fortunately, services like ChatGPT offer easy-to-use APIs, allowing for the quick development of custom internal tools to streamline experimentation.
To demonstrate this pattern, we developed a small service that allows you to upload a PDF document - screenplays make a fun example - and ask questions about them:
You can take a look at the code and play with the service at home. The service consists of a simple UI implemented in Svelte and a Python backend implemented with FastAPI which takes care of calling the OpenAI API.
Evaluating responses
While it is almost deceptively easy to get started with LLMs, it is a real challenge to evaluate the quality of results rigorously and find ways to improve results consistently.
A custom domain-specific UI, like the one sketched above, can be an instrumental tool for evaluations. Depending on your specific needs, you can make it easy to observe relevant inputs and outputs quickly and incorporate elements of automated testing as necessary.
The goal is to allow you to iterate prompts, data, and new models quickly:
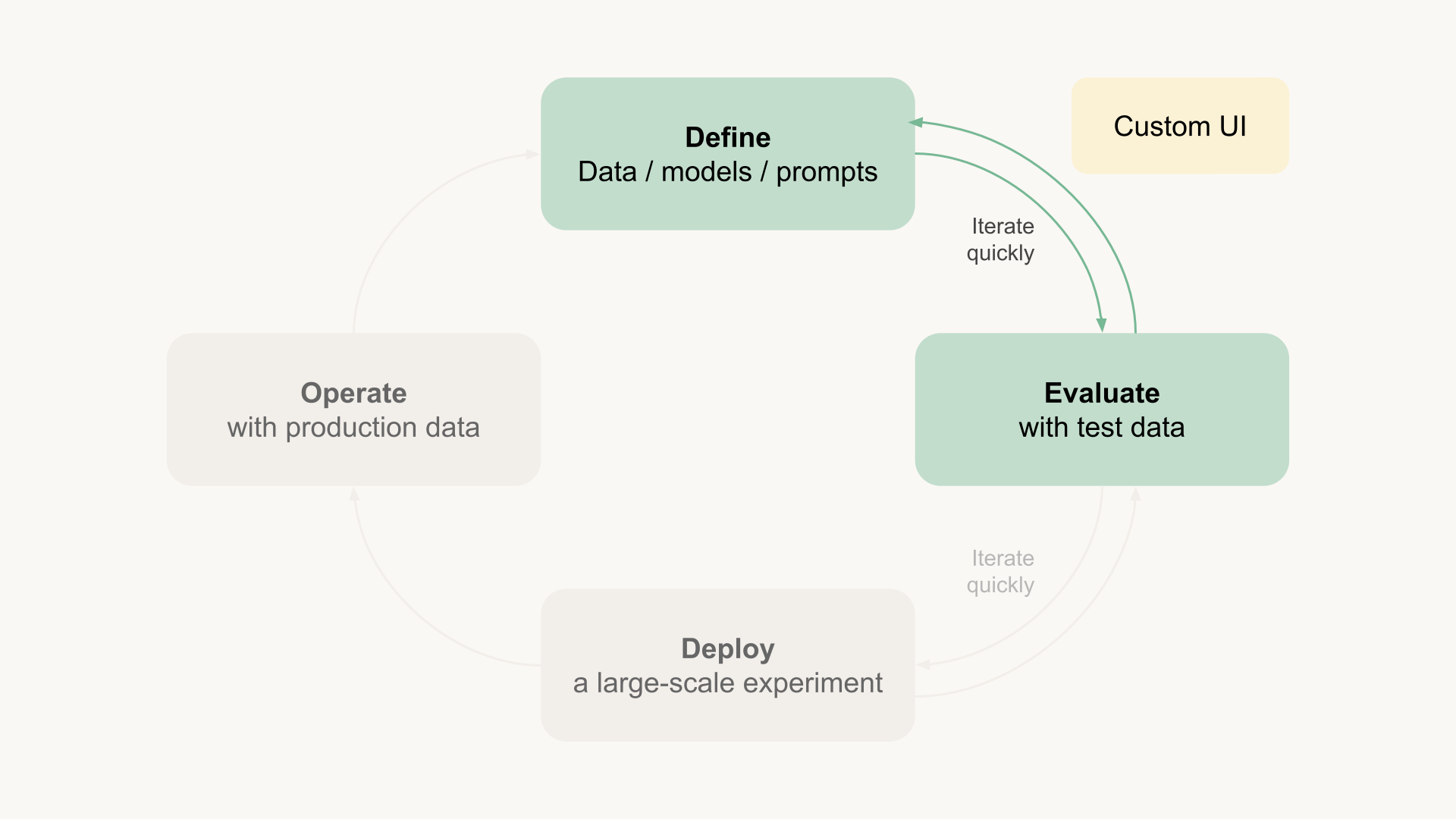
This approach aligns with the insightful notes about LLM evaluation by Hamel Husain, who has helped build a number of successful LLM products. Quoting his learnings:
- Remove ALL friction from looking at data.
- Keep it simple. Don’t buy fancy LLM tools. Use what you have first.
- You are doing it wrong if you aren’t looking at lots of data.
- Don’t rely on generic evaluation frameworks to measure the quality of your AI. Instead, create an evaluation system specific to your problem.
Automating document understanding
After engineering prompts, choosing models, and evaluating with test data, you are convinced that the project shows promise. What next?
There are a few practical challenges, similar to any data or modeling pipeline that needs to move to production:
Using real data - Especially if you are dealing with sensitive data, say, medical records, it is not feasible to use real data for testing. By nature, the production system will need to process real data, which necessitates a secure production environment with well-defined processes and policies for data access.
Testing at scale - Our evaluation UI may be able to host a small test harness, but we need more compute power to see how the setup works at scale, potentially processing millions of documents.
To address these challenges, which are common to any large-scale data processing task, a scalable compute environment is essential. While major data warehouses like Snowflake and Databricks can handle these tasks, often at a significant cost, there is no inherent need to use a data warehouse since the task does not require SQL or Spark.
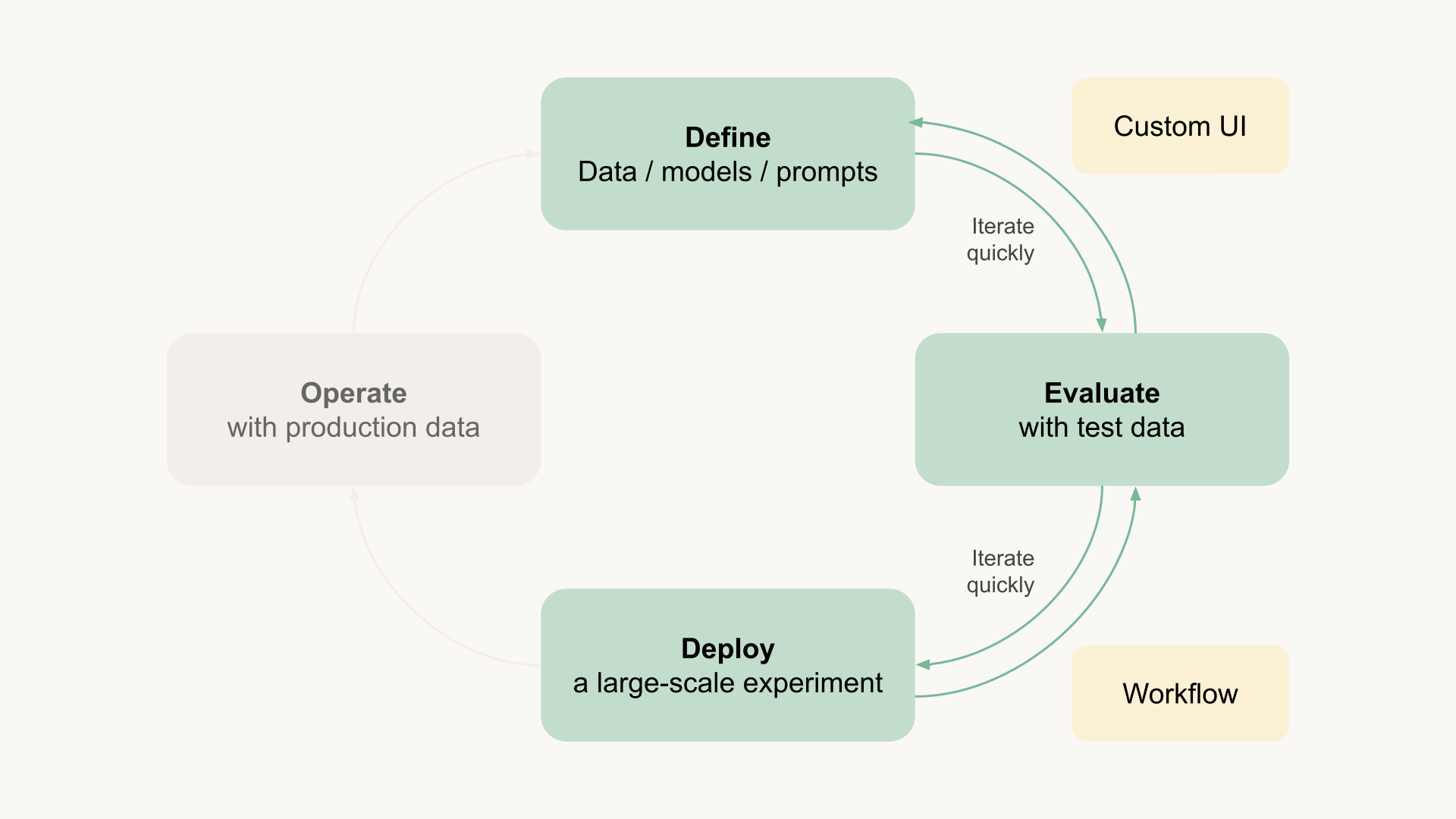
As an example, this Metaflow flow reads a set of PDF documents and processes them in parallel, producing a set of embeddings that can be used to query the documents. You can run the flow in your own cloud account, potentially handling millions of documents in parallel, using your own cloud instances without extra cost:
If security and scalability are concerns, you can run the flow on Outerbounds. As an extra benefit, you will be able to define flexible policies for evaluating new ideas and deploy them as experiments that can run in parallel with the production version, ensuring a safe, paved path from the evaluation stage to production.
Production-grade document understanding
Once in production - imagine a system processing, say, insurance claims as they come in - there are a few extra concerns.
Firstly, the system shouldn't fail. A consequence of LLMs being so accessible is that almost anyone with basic Python skills can create compelling prototypes, overlooking engineering best practices for building and operating robust production systems. Despite the excitement around AI, it hasn't resolved typical DevOps and infrastructure challenges, which you can either solve in a DIY manner or rely on managed infrastructure.
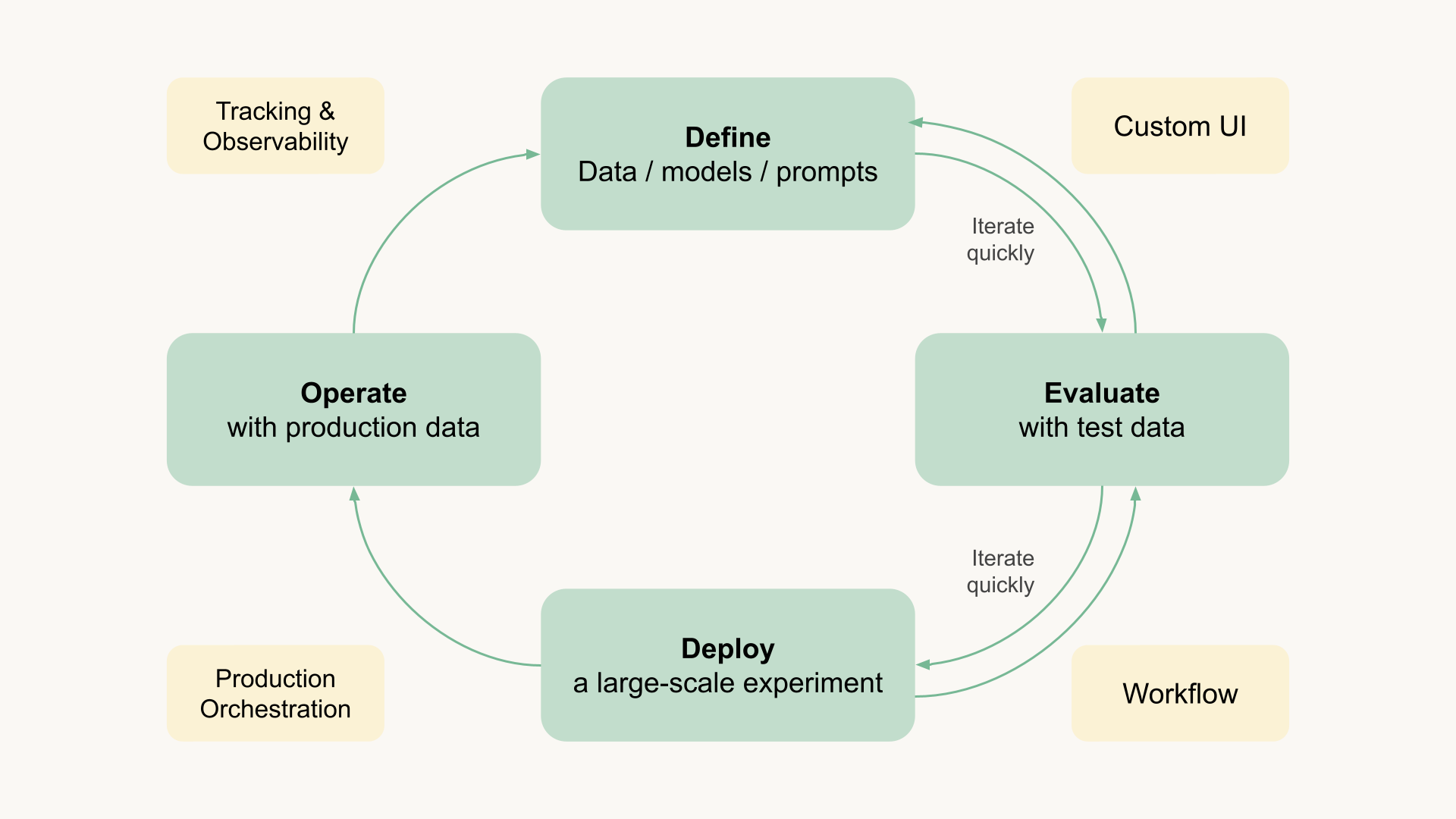
Secondly, you need to be able to move fast without breaking things. The LLMs of today suffer from planned obsolescence. Providers like OpenAI roll out new versions of models frequently, often with little advance notice or visibility, making it non-trivial to operate stable and predictable production systems.
In a fast-moving environment like this, it is critically important to be able to track model and prompt versions and their performance, all the way from evaluation and experimentation to production and back.
Private, scalable, cost-efficient LLMs with NVIDIA NIM
Like any other software component, LLMs present the choice of insourcing vs. outsourcing. You can choose to use a 3rd party managed LLM, such as ChatGPT APIs by OpenAI, or you can set up an open-source LLM, such as Llama3 or models by Mistral, in your own environment.
The pros and cons are well known: Managed APIs provide convenience, while private solutions provide more flexibility, privacy, and control. In the case of LLMs, the questions of accuracy and cost are hotly contested between the two approaches.
In 2023, hosting LLMs in-house was hardly an option, due to the limited selection of high-quality open LLMs, and the complexity and immaturity of the stack required to use them effectively. In 2024, the situation has improved significantly. Today, there is no shortage of high-quality, permissively licensed LLMs, with new ones being released weekly.
While models are plentiful, setting up an inference stack to serve open models remains a challenge, if performance and cost are concerns. Recognizing this, NVIDIA has started optimizing and packaging open models as a new offering, NIM Inference Microservices, combining the convenience of a packaged solution with the benefits of being able to run and control models in your own environment.
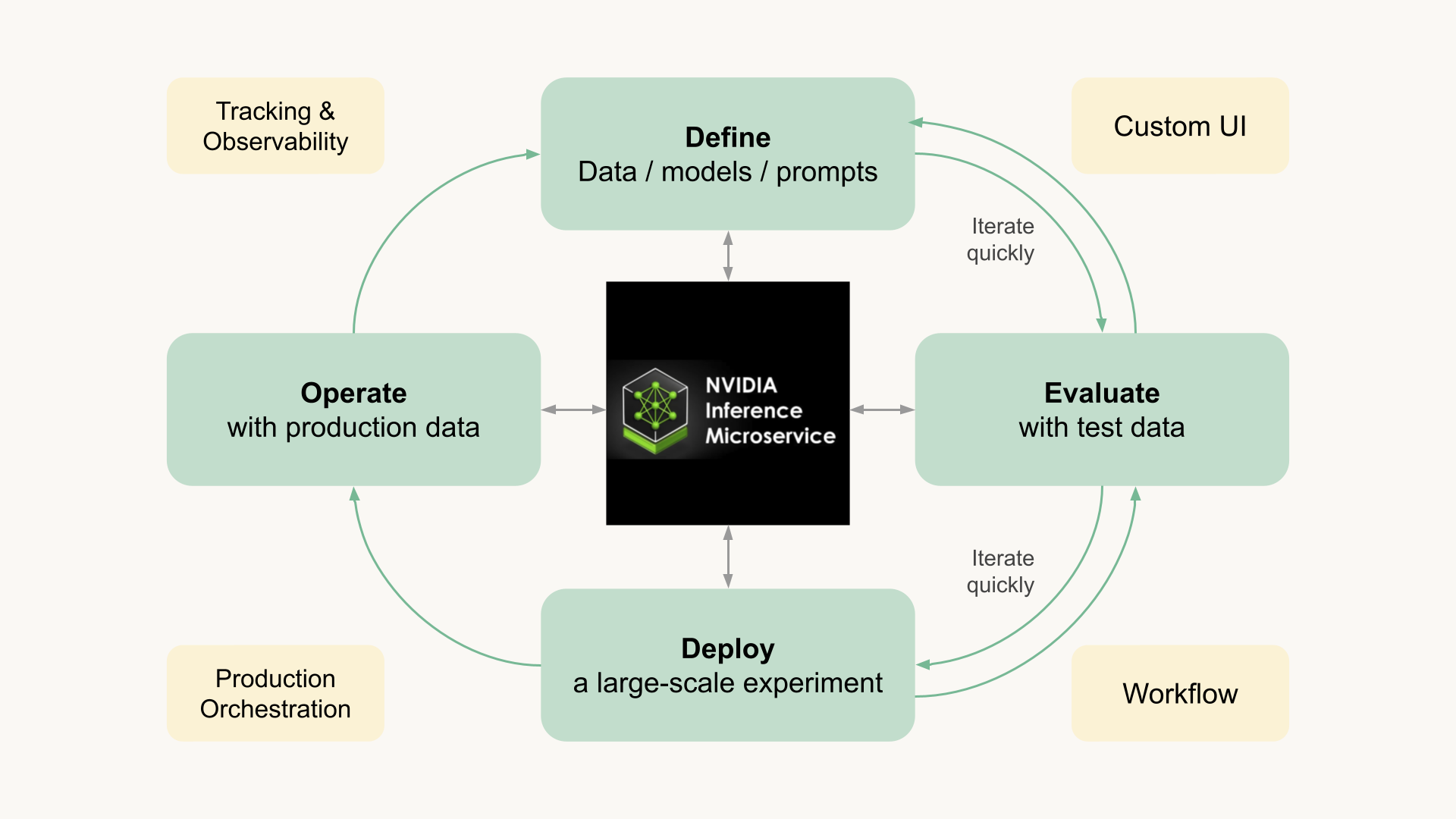
At Outerbounds, we believe that LLMs will become core building blocks of many systems in the future - similar to databases today, so we are eager to integrate NVIDIA's pre-packaged LLMs a part of the platform, completing the stack required to build production-grade document understanding systems, amongst many other use cases.
Using a private LLM can be as easy as using a ChatGPT API - simply add @nim in your
flow, denoting what model you want to access:
MODEL = 'meta/llama3-8b-instruct'
PROMPT = "answer with one word HAPPY if the sentiment of "
"the following sentence is positive, "
"otherwise answer with one word SAD"
@nim(models=[MODEL])
class ReviewSentimentFlow(FlowSpec):
...
@step
def prompt():
llm = current.nim.models[MODEL]
for review in reviews:
prompt = {'role': 'user', 'content': f'{PROMPT}: {review}'}
chat_completion = llm(messages=[prompt], model=MODEL)
The @nim decorator ensures that the desired model will be available during
the execution of the flow - securely running in your environment, at any scale
needed, allowing you to process even millions of documents in parallel without
running into rate limits - or breaking the bank.
For instance, you can analyze sentiment of e-commerce reviews in less than 100 lines of code, parallelizing the processing for maximum throughput:
This workflow meets the requirements for production-grade document understanding:
It runs securely in your cloud account, the LLM included, ensuring that no data leaks outside the company's premises.
It can process any number of documents quickly without rate limits, using state-of-the-art LLMs.
It runs in a highly available manner, processing new production data automatically, with all results logged automatically.
To close the loop, the workflow can be developed and tested locally without hassle, safely isolated from production to ensure quick iterations.
Get started
If you want to start building systems like this in your own environment, you can deploy Outerbounds in your cloud account in 15 minutes. To learn more, you can join over 4000 data scientists and ML/AI engineers in Metaflow Slack.