XGBoost batch inference
Introduction
Welcome to the XGBoost batch inference journey!
📈 Learning objectives
The goal of this self-contained lesson is to build a production-ready system to handle time series forecasting at scale. You will see how to connect familiar notebook environments and ML/AI experimentation to scheduled and event-driven batch inference pipelines. While we focus on a time series problem, the infrastructural patterns are generally applicable to any form of supervised learning.
You will see many of the features of Outerbounds in action, while learning how to interact with the Outerbounds UI. Running the content end-to-end includes:
- Start with exploratory data analysis (EDA) and building time series forecasting models in notebooks.
- Then, operationalize your code through Metaflow workflows. A key pattern demonstrated in this journey is structuring ML repositories to share modules between notebooks and workflow code, ensuring consistency from development environments to production and back.
- The pattern repeats for inference, with a notebook and corresponding workflow.
- Along the way, you will see how to deploy and monitor workflows in the Outerbounds UI.
- The lesson closes with an example you can branch from to adapt to your problems and start improving it.
Compute pool setup
To run this code you need to run notebooks on a workstations and Metaflow tasks on Kubernetes. Both of these run inside compute pools. In this section you will set up access to a compute pool suitable for running the workstations and the Metaflow workflows.
In another tab, open the Compute Pools view. Click on the Add Pool button and create a compute pool ≥14 CPUs named xgboost-tutorial.
Download the content to your workstation
This command downloads the content to your workstation:
outerbounds tutorials pull --url https://outerbounds-journeys-content.s3.us-west-2.amazonaws.com/main/journeys.tar.gz --destination-dir ~/learn
🧪 Run the baseline notebook
Let's get started with the baseline notebook. Open the notebook in 00-baseline-nb/main.ipynb and run through it in your workstation. User's choice, you can study the code carefully, or go all in and click Run All.
🏭 Run the baseline workflow
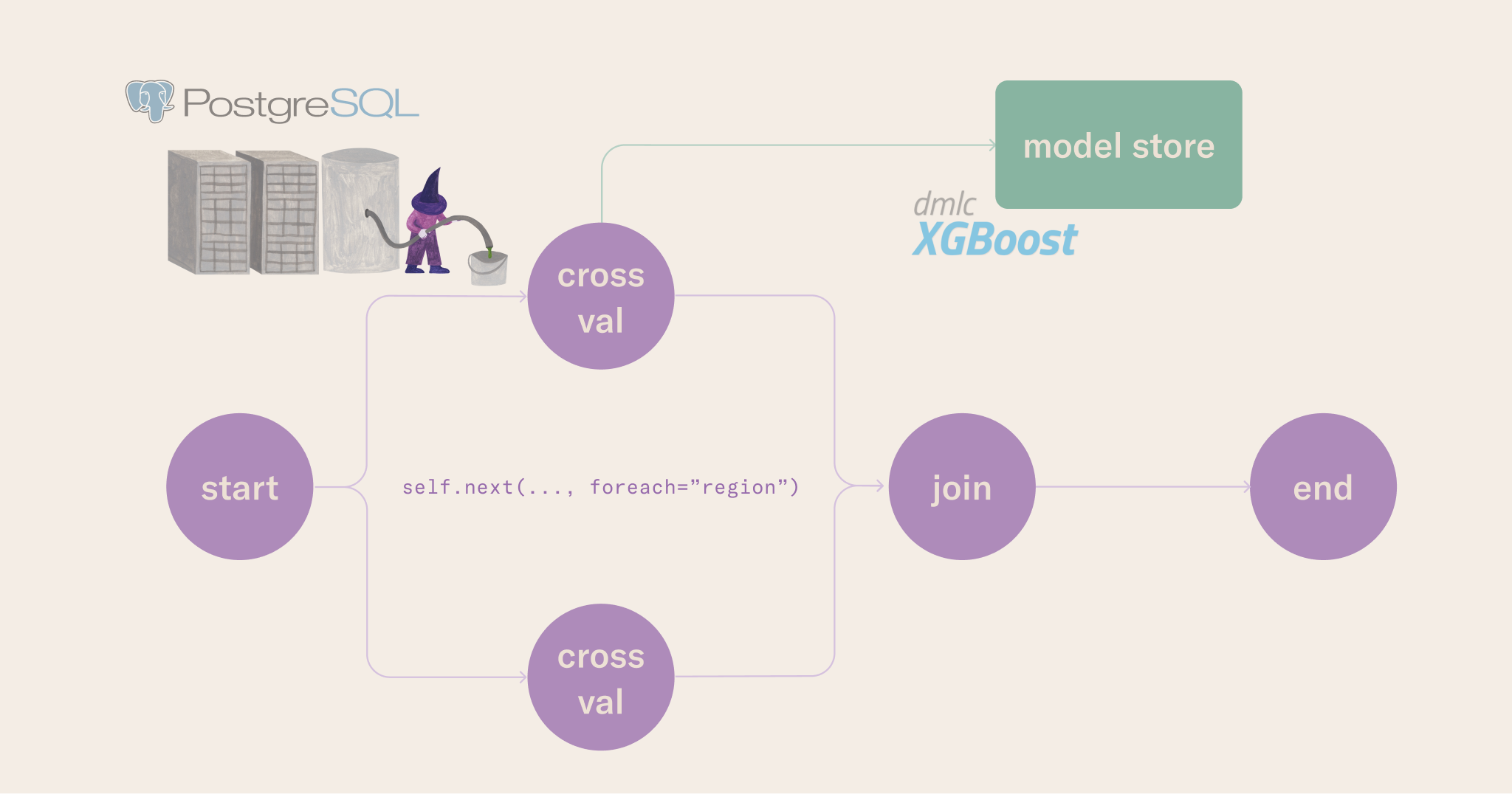
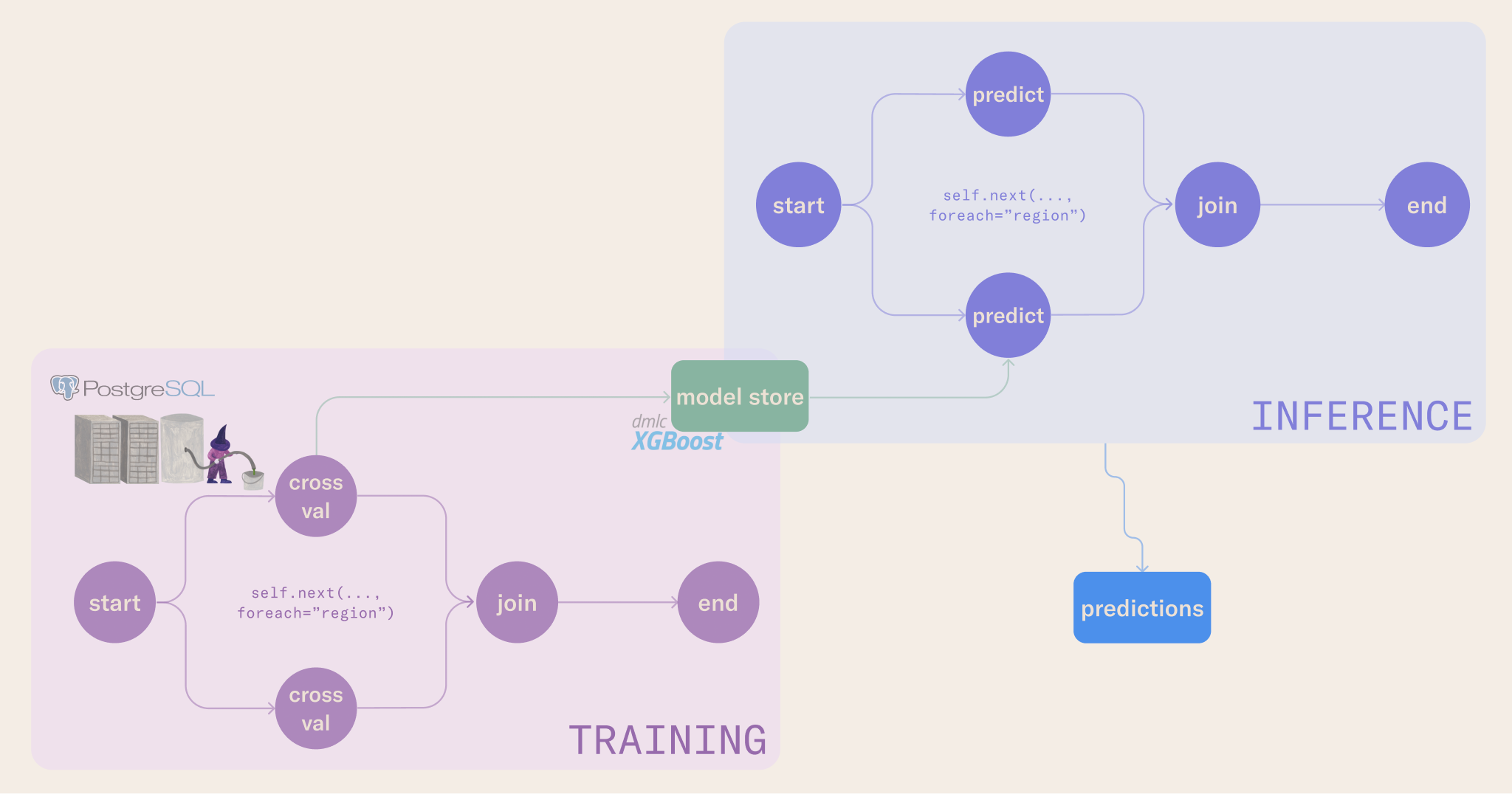
In this section, we will migrate the business logic from the notebook to a workflow in train_baseline.py.
- The following command structured like
python flow.py ... run ...shows the general pattern for manually launching Metaflow runs. - The
--environment=fast-bakeryflag tells Outerbounds how to build the environment for each step. Read more about . - The
--with kubernetesflag tells Outerbounds to run the workflow on Kubernetes. Read more about . - The
--smokeflag trains for one region for one CV fold. This pattern is useful to save cost/time during development and integration testing. - You should see the CLI output the progress of the workflow, and it will include a link to the the Runs view for that specific run you can monitor the run in the Outerbounds UI.
cd ~/learn/ml-end-to-end/01-baseline-flow
python flow.py --environment=fast-bakery run --with kubernetes:compute_pool=xgboost-tutorial --smoke True
If you'd like to launch the full workflow for all regions in the data, run without the --smoke flag:
python flow.py --environment=fast-bakery run --with kubernetes:compute_pool=xgboost-tutorial
Feel free to spend some time at this stage to understand the code and the workflow structure. Before considering complex design patterns, multiplayer modes, and advances use cases, this is a good time to pause and reflect on how you'd like to design your ML platform environments to maximize your productivity when iterating back and forth between notebooks, or your preferred development interface, and workflows.
🧪 Run the baseline inference notebook
This section connects the baseline model to a batch inference pattern. Open the notebook in 02-inference-nb/main.ipynb and run through it in your workstation. This is the first time you will see how to fetch the model trained inside a workflow, using .
jupyter execute 02-inference-nb/main.ipynb
🏭 Run the baseline inference workflow
Similar to the baseline workflow, this section runs the inference workflow in flow.py. Like in the previous notebook, the inference workflow will fetch the model stored via the upstream training workflow and execute batch inference for the next day in the forecast. Predictions are then stored in a Metaflow artifact, versioned by the flow run ID; this makes them easy to fetch in downstream consumer applications and to trace back to the original data and model that produced the predictions.
To run the workflow, use the following command:
cd ~/learn/ml-end-to-end/03-inference-flow
python flow.py --environment=fast-bakery run --with kubernetes:compute_pool=xgboost-tutorial --smoke True
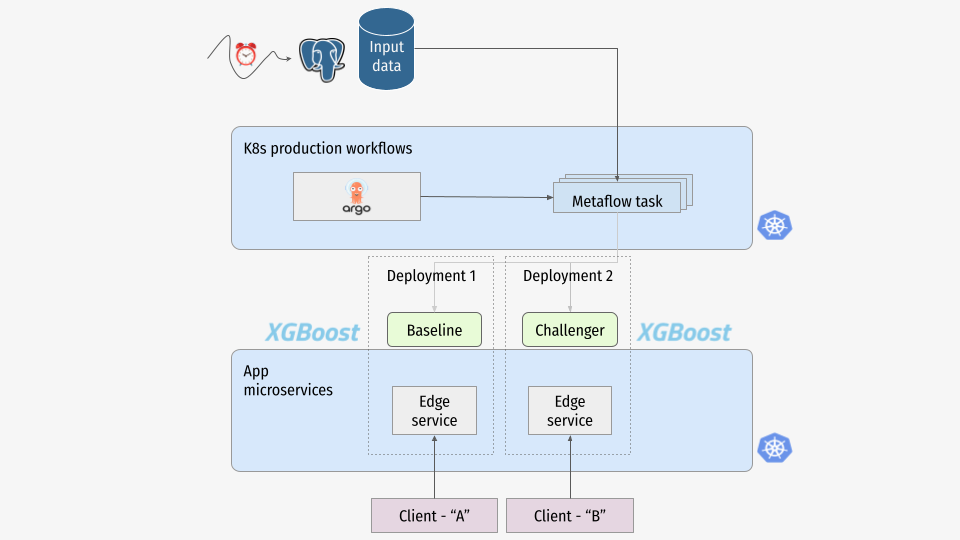
🚀 Deploy the sensor workflow
So far, we've run the workflows manually. This section deploys a workflow that runs every 5 minutes - you can modify this interval in the @schedule decorator - checking for updates to the database and triggering the inference workflow when new data is available.
Hello Argo Workflows
In this and the following sections, there are two key commands to understand:
python flow.py ... argo-workflows create- This command packages the workflow and deploys it to the production orchestrator.python flow.py ... argo-workflows trigger- This command manually triggers the workflow to run on the production orchestrator. In later lessons, we'll configure the workflow to run on a schedule or based on events other than a manual trigger.- For more details you can which Outerbounds platform builds on top of.
cd ~/learn/ml-end-to-end/06-sensor-flow
python flow.py --environment=pypi argo-workflows create
🔍 Monitor deployed workflows
You can monitor the deployed workflows in the Outerbounds UI Deployments view. Click on the workflows to see details and how they connect to the Runs view. You can also trigger workflows manually from the UI.
⏰ Deploy the baseline training workflow
In this section, we will deploy the baseline flow to the production orchestrator built into your Outerbounds deployment. We will deploy the workflow with the @schedule decorator, so we retrain the model at a regular interval.
The choice to do retraining on a schedule is use case dependent. In some cases, you may want to retrain based on triggers like detecting change points, model performance degradation, or other exogenous events.
cd ~/learn/ml-end-to-end/01-baseline-flow
python flow.py --environment=fast-bakery argo-workflows create
python flow.py --environment=fast-bakery argo-workflows trigger # manual run
⚡️ Deploy the baseline inference workflow with @trigger
In this section, we will deploy the inference flow to the production orchestrator built into your Outerbounds deployment. Where the training workflow is scheduled, the inference workflow is triggered by the sensor workflow when new data is available. In general, this pattern makes sense when you have a clear separation between training and inference, and you want to compute inferences as soon as new data is available.
cd ~/learn/ml-end-to-end/03-inference-flow
python flow.py --environment=fast-bakery argo-workflows create
python flow.py --environment=fast-bakery argo-workflows trigger # manual run
Next steps
In this journey, you have built a production-ready system to handle time series forecasting at scale. You have seen how to connect familiar notebook environments and ML/AI experimentation to scheduled and event-driven batch inference pipelines.
You have seen many of the features of Outerbounds in action, while learning how to interact with the Outerbounds UI.
Now you can build systems that enable complex experimentation and deployment scenarios.
For example, you can move on to improving the features and modeling. For the Outliers still reading, there is a starter pack with more advanced time series feature engineering methods inside the repository.