Natural Language Processing - Episode 4
This episode references the Python script branchflow.py.
In the previous episode, you saw how we constructed a basic flow to compute the baseline for our NLP task. In this lesson, we will learn how to incorporate the model as well as show you how to use branching to compute things in parallel. At the end of this lesson, you will be able to:
- Refactor a training code into a flow.
- Process data and train models in parallel with branching.
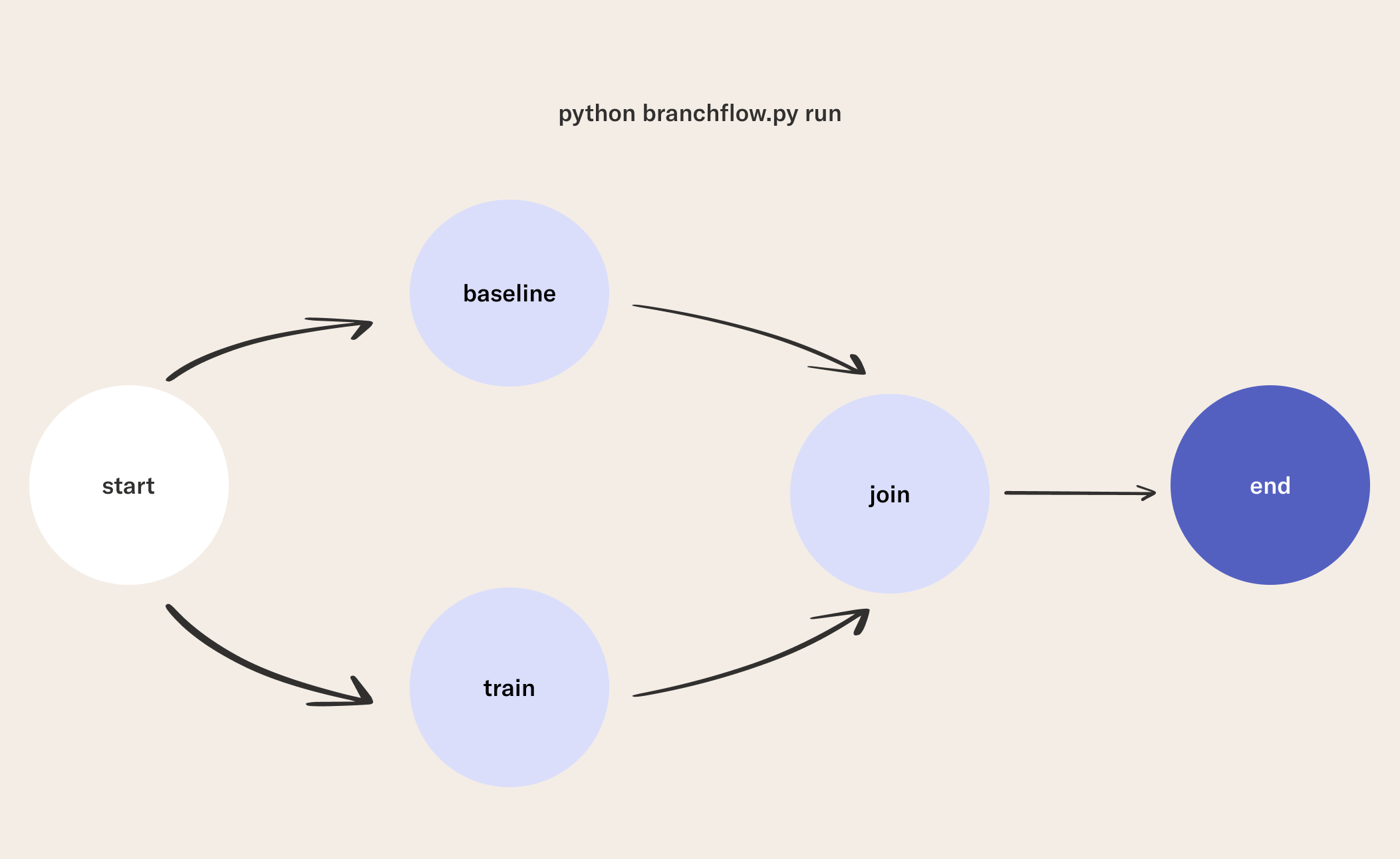
1What is Branching?
Branching is a powerful feature in Metaflow that allows you complete steps in parallel instead of in a linear fashion. To demonstrate this feature, we will construct our baseline and train steps as two branches that will execute in parallel. It should be noted that anytime you use branching, you also need a join step to disambiguate the branches, which you can read more about here.
2Write a Flow
In this flow, we will modify the start and join steps to achieve branching, as well as add a train step that will train our model.
Below is a detailed explanation of the changes we are making to our original flow:
- Create a branching workflow to create a baseline and candidate model in parallel in the
baselineandtrainsteps.- When we call
self.next(self.baseline, self.train), this creates a branching flow that will allow thebaselineandtrainsteps to run in parallel.
- When we call
- Add a training step The
trainstep uses a neural-bag-of-words model to train a text classifier.- We import the
NbowModelmodule we created in Lesson 1. - We save this model in a special way by setting the
model_dictproperty of our custom model toself.model_dict, which has the effect of storing this data in Metaflow's artifact store, where data is versioned and saved automatically.
- We import the
- Add a join step: In this step, we will load our model using
NbowModel.from_dict(self.model_dict)as well as disambiguate the data in our branches.- The join step can disambiguate data by referring to a specific step in the branch. For example,
inputs.train.dfrefers to thetrainstep, and specifically thedfartifact stored in that step. - We print the performance metrics of our model and the baseline in this join step.
- The join step can disambiguate data by referring to a specific step in the branch. For example,
from metaflow import FlowSpec, step, Flow, current
class BranchNLPFlow(FlowSpec):
@step
def start(self):
"Read the data"
import pandas as pd
self.df = pd.read_parquet('train.parquet')
self.valdf = pd.read_parquet('valid.parquet')
print(f'num of rows: {self.df.shape[0]}')
self.next(self.baseline, self.train)
@step
def baseline(self):
"Compute the baseline"
from sklearn.metrics import accuracy_score, roc_auc_score
baseline_predictions = [1] * self.valdf.shape[0]
self.base_acc = accuracy_score(
self.valdf.labels, baseline_predictions)
self.base_rocauc = roc_auc_score(
self.valdf.labels, baseline_predictions)
self.next(self.join)
@step
def train(self):
"Train the model"
from model import NbowModel
model = NbowModel(vocab_sz=750)
model.fit(X=self.df['review'], y=self.df['labels'])
self.model_dict = model.model_dict #save model
self.next(self.join)
@step
def join(self, inputs):
"Compare the model results with the baseline."
import pandas as pd
from model import NbowModel
self.model_dict = inputs.train.model_dict
self.train_df = inputs.train.df
self.val_df = inputs.baseline.valdf
self.base_rocauc = inputs.baseline.base_rocauc
self.base_acc = inputs.baseline.base_acc
model = NbowModel.from_dict(self.model_dict)
self.model_acc = model.eval_acc(
X=self.val_df['review'], labels=self.val_df['labels'])
self.model_rocauc = model.eval_rocauc(
X=self.val_df['review'], labels=self.val_df['labels'])
print(f'Baseline Acccuracy: {self.base_acc:.2%}')
print(f'Baseline AUC: {self.base_rocauc:.2}')
print(f'Model Acccuracy: {self.model_acc:.2%}')
print(f'Model AUC: {self.model_rocauc:.2}')
self.next(self.end)
@step
def end(self):
print('Flow is complete')
if __name__ == '__main__':
BranchNLPFlow()
3Run the Flow
python branchflow.py run
We can see from the Metaflow logs that our model looks promising in that it is performing better than the baseline! However, computing the baseline isn't just meant for the logs! We should use the baseline alongside other tests to gate which models make it to production.
In the next lesson, you will learn how to test our models and use tagging to manage which models are promoted to production.