Versioning Code and Models
Versioning code is standard practice in all software domains including machine learning. However, there are nuanced but important differences between how traditional software is developed, versioned, and deployed compared to data science. Consider the typical workflows illustrated below with a traditional software development process in yellow and a machine learning development process in purple:
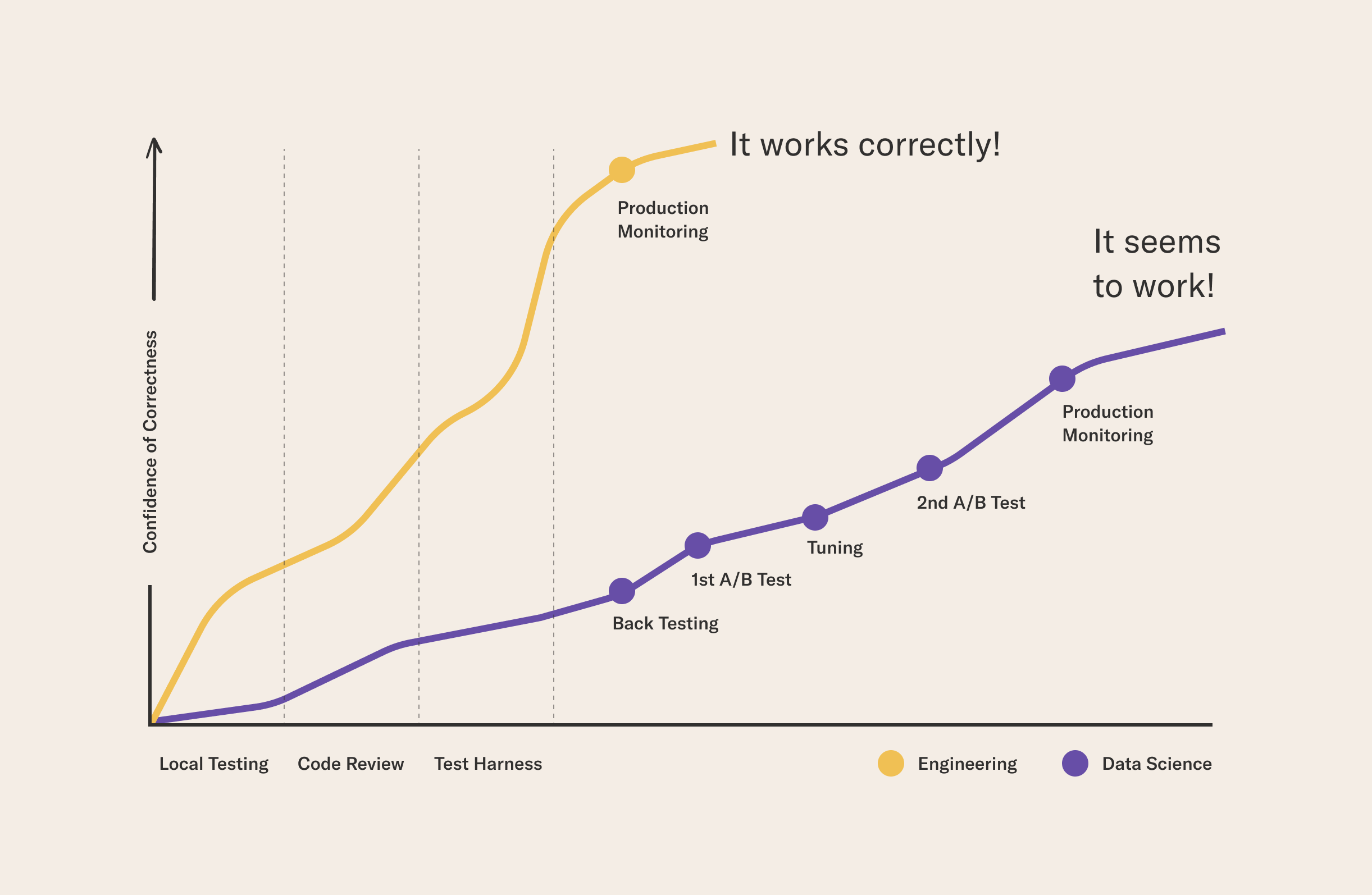
Both types of workflows start a path from prototyping to deployment in similar places - with developing code, likely in an IDE or text editor. Often, local testing is performed before submitting a pull request in the team’s version control system. The request is reviewed and thoroughly tested with a CI/CD process before being deployed.
Tracking the whole lifecycle of a project is not easy, in particular when many disparate systems are involved. After decades of trial and error, traditional software engineering is starting to have solid patterns of this, often accomplished by structuring all tracking around Git - hence the term GitOps.
In the case of machine learning, these steps are often not sufficient for ensuring that the system works correctly in all circumstances. To increase our confidence of correctness, additional steps, such as backtesting and A/B testing are needed, often followed by further iterations of tuning the system. Even after implementing these steps, the nature of machine learning and constantly changing data make it harder to produce systems we are fully confident in.
Iterative Development Processes in Machine Learning
The development process of machine learning is rooted in experimentation. Compared to traditional software engineering where it is possible to review and validate the correctness of a piece of code, data science is more empirical. It is hard to know in advance what data set versions and models yield the best results, which necessitates highly iterative development. It isn’t always clear in which order the steps should be done or when the data is sufficiently prepared for modeling. Observations during modeling and deployment phases may require further iteration in the data and modeling phases. In short, it takes a longer time and more iterations to convince ourselves that an ML system works correctly compared to a traditional software system. This has implications to how ML systems should be versioned. As a starting point, it is a good idea to use version control systems like Git for code and CI/CD systems to automate workflows but the non-linearity and interdependency of data and modeling phases of ML add new versioning considerations.
Versioning Models and Model Registries
An ML model is a combination of code and data. The code expresses the model architecture and often the training code that is used to fit the model. The data includes the parameters of a trained model, and possibly hyperparameters needed for training the model. The code can be versioned in a version control system like Git, and models with their parameters can be serialized e.g. as Metaflow artifacts which are stored and versioned automatically. Besides tracking the models themselves, we should track the state of the development and deployment process. For instance, machine learning deployment strategies lead to many model versions being deployed in production concurrently. This makes it important to catalog model versions somewhere they can be easily discovered and deployed into the production environment.
The term model registry describes a system where deployable model versions are recorded. The registry might also include information about how to deploy models or metadata like what lifecycle stage a model is in. When a model produces subpar or unexpected results in production, it is important to know which model exactly produced the results, and how and when the model itself was produced, which is the information that a model registry can help to provide The model registry can be provided by the deployment tool of your choice, you can install a separate service for it, or you can rely on Metaflow’s artifacts to track the lineage of models and keep deployments organized.
How do I?
Reproduce machine learning workflows